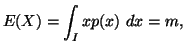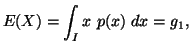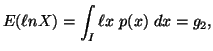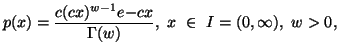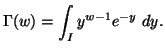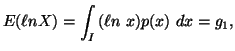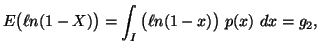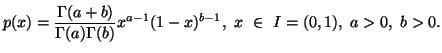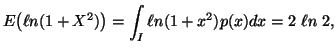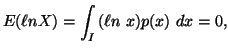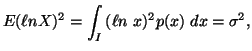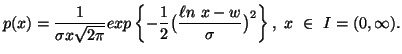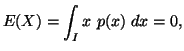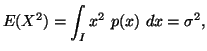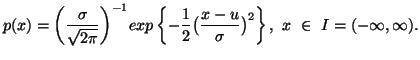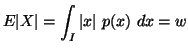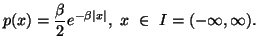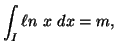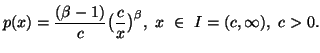Probability distributions plays a key role in statistical analysis.
This is because standard theoretical distributions are indeed the statistical
models for different kinds of situations. For example, consider a random
experiment, the outcome of which can be classified one of two mutually
exclusive and exhaustive ways, say, success or failure. Then if the experiment
is repeated n times, the binomial distribution is the model in determining
the probability of number of successes. The Poisson distribution
may serve as an excellent mathematical model in a number of situations.
The number of road accidents in some unit of time, the number of insurance
claims in some unit of time, the number of telephone calls at a swichtboard
in some unit of time etc.. are all governed by the Poisson model.
An another example, the gamma distribution is frequently used as the
probability model for waiting times; for instance, in testing bulbs until
they fail, then if the random variable ![]() is the time needed to obtain exactly
is the time needed to obtain exactly ![]() failures, where
failures, where ![]() is a fixed positive integer, the distribution of
is a fixed positive integer, the distribution of ![]() is the gamma distribution. Perhaps, the most used distribution in statistical
analysis is the normal distribution. It is encountered in many different
situations, e.g., the score on a test, the length of a newly born child,
the yield of a grain on a plot of ground, etc.. The normal distribution
can also be used as an approximation to many other distribution, e.g.,
Poisson distribution, Bionomial distribution etc..
is the gamma distribution. Perhaps, the most used distribution in statistical
analysis is the normal distribution. It is encountered in many different
situations, e.g., the score on a test, the length of a newly born child,
the yield of a grain on a plot of ground, etc.. The normal distribution
can also be used as an approximation to many other distribution, e.g.,
Poisson distribution, Bionomial distribution etc..
In this subsection, we use maximum entropy principle to characterize important probability distributions. This provides not only a new way of characterizing them but also brings out an important underlying unity in these distributions (ref. Gokhale, 1975 [40], Kagan et al., 1973 [53], Kapur, 1989 [60];1992 [62]).
In the following property we characterize via entropy maximum
principle various probability distributions subject to the constraint ![]() ,
, ![]() ,
,![]() along with others, where the interval I vary accordingly.
along with others, where the interval I vary accordingly.
Property 1.76. We have